Auto-starting ten Amazon machine learning instances
UPDATE
This is part three on automating deep learning training sessions as software builds.
Disclaimer
Use any of this at your own risk. Automating machine bootup and shutdowns can be a tricky thing and I will not guarantee that the configuration below will always work.
TLDR;
Rent a cheap machine as a master and deploy this listening script to fire up a couple of Amazon machines to train your model.
Part one is here. Part two is here.
Firing up ten Amazon machines
Previously, I wrote on the wonders of using a build server to ‘build’ deep learning models as part of a continuous delivery pipeline of sorts. You could even go as far as publish the pre-trained and saved model as a build artifact, a ‘release’ of your exertions. We will look into that another time, but having a full build trail of a pre-trained model could be part of the answer to the machine learning reproducibility crisis!
Then, I wrote on why it is important to repeat the training results for a model to get a sense of the spread of the performance of your model. Many experiments in exact sciences hinge on repeated results. The Higgs boson was only confirmed after repeated measurements with a 5-sigma or one in 3.5 million chance the hypothesis would be false.
We’re not going to be that stringent, but I did go as far as to say that if you tweak your model to produce a 0.02 point increase in performance (say, accuracy) you can only claim victory if you can reproduce this gain a couple of times, because deep learning most often includes a level of randomness: in the selection of the batch and validation samples, the initialisation of the network. This is not a bad thing: we like our model to generalize as best as possible. We can’t select the data we’re going to throw at it in production either: it’s very probably going to be random.
In embracing this randomness and the spread that our model performance is going to exhibit, I plead to do repeated experiments on the same model setup using (at least) ten machines. These I rent from Amazon and, as these machines are costly and not needed all of the time, I’m going to automate the crap out of it. Here is what I did.
Listening
First, we need a machine that is always on. It is our master machine and it has the authority to fire up other machines if some change in our repository is detected. For this, we keep things as simple as possible, as simplicity is our friend. The more complexity we introduce, the more likely it is to break at some time.
I used a python script to set up a service. For this script, you will need a couple of things. Firstly, it is going to read a yaml file called instances.yml from the same directory the script is run. It is going to look like this:
ec2:
- i-11111111
- i-222222222
- i-333333333
- etcetera
It will contain the ec2 instance ids you are going to use to do your training sessions. These instance ids you can find in your Amazon EC2 console. You want to start with one machine learning instance to test the correct workings of your automation setup. Then, if everything is working to satisfaction, you can create a private image of your machine and create as many ‘clones’ from the first test machine image.
Secondly, the script is going to read a couple of environment variables:
- SLACK_API_TOKEN: you can generate this here. For more information, see here. Although this part is not mandatory, I cannot recommend enough the importance of some kind of notification service to follow around the startup and shutdown of your machines. If something goes wrong, you should know. Slack does this brilliantly.
- SLACK_CHANNEL: the channel name that you designate for messages on starting and stopping machines. I suggest something like
#monitoringor something. You should create the channel first. - SECRET_TOKEN: this is the canonical environment variable name as recommended by GitHub for the webhook system. You need to set this webhook for the repository you want monitored. You do this by going to https://github.com/{your_username}/{repo_name}/settings/hooks and by clicking
Add webhook: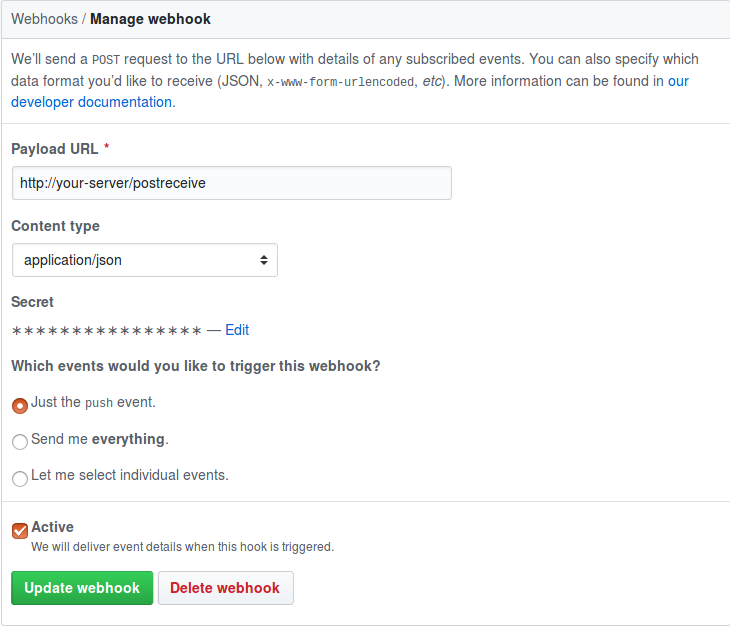 You generate the token using
You generate the token using ruby -rsecurerandom -e 'puts SecureRandom.hex(20)'as suggested here
Docker compose
I made sure these environment variables were set, by Dockerizing the service with a Docker compose configuration in a docker-compose.yml file:
ml_manager:
build:
.
restart: unless-stopped
volumes:
- ./:/ml_manager
ports:
- "80:4000"
environment:
- SLACK_API_TOKEN=my_slack_api_token
- SLACK_CHANNEL=#some_channel
- SECRET_TOKEN=secret_github_commit_hook_token
- AWS_REGION_NAME=eu-west-1
- AWS_ACCESS_KEY_ID=aws_secret_key_id
- AWS_SECRET_ACCESS_KEY=aws_secret_access_key
Which you can run on the listening or master server using docker-compose up -d Of course you need to set proper tokens for the placeholder text here. Also, you need a web server with a reverse proxy with the same route as set in your webhook configuration, pointing to your listening service, a system which I described earlier here. Make sure NOT to commit any of this in an open repository. The information will certainly be found and someone will start mining bitcoins, hacking or spambotting using YOUR account on YOUR expenses!
Dockerfile
You now of course need a simple Dockerfile:
FROM python:latest
COPY requirements.txt /requirements.txt
RUN pip3 install -r /requirements.txt
WORKDIR /ml_manager
CMD ["python3", "manager.py"]
Which comes with a requirements.txt file for the python dependencies:
boto3
slackClient
github_webhook
pyyaml
The python script
import http
import os
from datetime import datetime
import boto3
import yaml
from flask import Flask
from github_webhook import Webhook
from slackclient import SlackClient
SCRIPT_NAME = os.path.basename(__file__)
TIMESTAMP = str(datetime.now()).replace(':', '.')
# Get environment variables
slack_token = os.environ.get('SLACK_API_TOKEN') # Slack is not required
if slack_token:
channel = os.environ['SLACK_CHANNEL'] # but it requires a channel if set
secret = os.environ['SECRET_TOKEN'] # You really need to set a webhook secret!
region_name = os.environ['AWS_REGION_NAME']
# Initialize frameworks
ec2_client = boto3.client('ec2', region_name=region_name)
ec2_res = boto3.resource('ec2', region_name=region_name)
app = Flask(__name__) # Standard Flask app
webhook = Webhook(app, endpoint='/postreceive', secret=secret)
# Slack notification function
def notify(signature, message):
if slack_token:
sc = SlackClient(slack_token)
sc.api_call("chat.postMessage", channel=channel,
text="Script " + signature + " notification: " + str(message))
def start_instance(instance):
running_instances = ec2_res.instances.filter(
Filters=[{'Name': 'instance-state-name', 'Values': ['running']}])
running_instances = [ri.id for ri in running_instances]
if instance in running_instances:
print(instance, 'already running')
else:
try:
response = ec2_client.start_instances(InstanceIds=[instance])
http_status = http.HTTPStatus(
response['ResponseMetadata']['HTTPStatusCode']).name
print('Start instance {}: {}'.format(instance, http_status))
notify(SCRIPT_NAME,
'started {} with response {}'.format(
instance, http_status))
except Exception as e:
this_instance = [i for i in ec2_res.instances.filter(
Filters=[{'Name': 'instance-id', 'Values': [instance]}])][0]
notify(SCRIPT_NAME,
'Error starting instance {}, status {} with {}'.format(
instance, this_instance.state, e))
# Read list of instances
with open('instances.yml') as f:
instances = yaml.load(f)
@app.route("/pushservice")
def status():
return "The push service is running"
@webhook.hook(event_type='push') # Defines a handler for the 'push' event
def on_push(data):
for instance in instances['ec2']:
start_instance(instance)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=4000)
Now, we can automatically fire up as much Amazon machine learning instances as we like! Of course, these will run forever until our credit card runs out. So, next, we’re going to see how we can automatically shut these instances down once they start to run idle.